The rapid-fire news cycle hurts pretty much everyone. It makes it hard to focus, hard to learn, and ultimately distorts the importance of events.
So today I’m traveling back in time one whole month for a reality check on DeepSeek R1, the impressive large language model released by a Chinese hedge fund in December.
On Monday, January 27, the debut of the DeepSeek iOS app caused Nvidia’s stock to crater 16% in a day.
Want to guess what has happened in the 24 days since then?
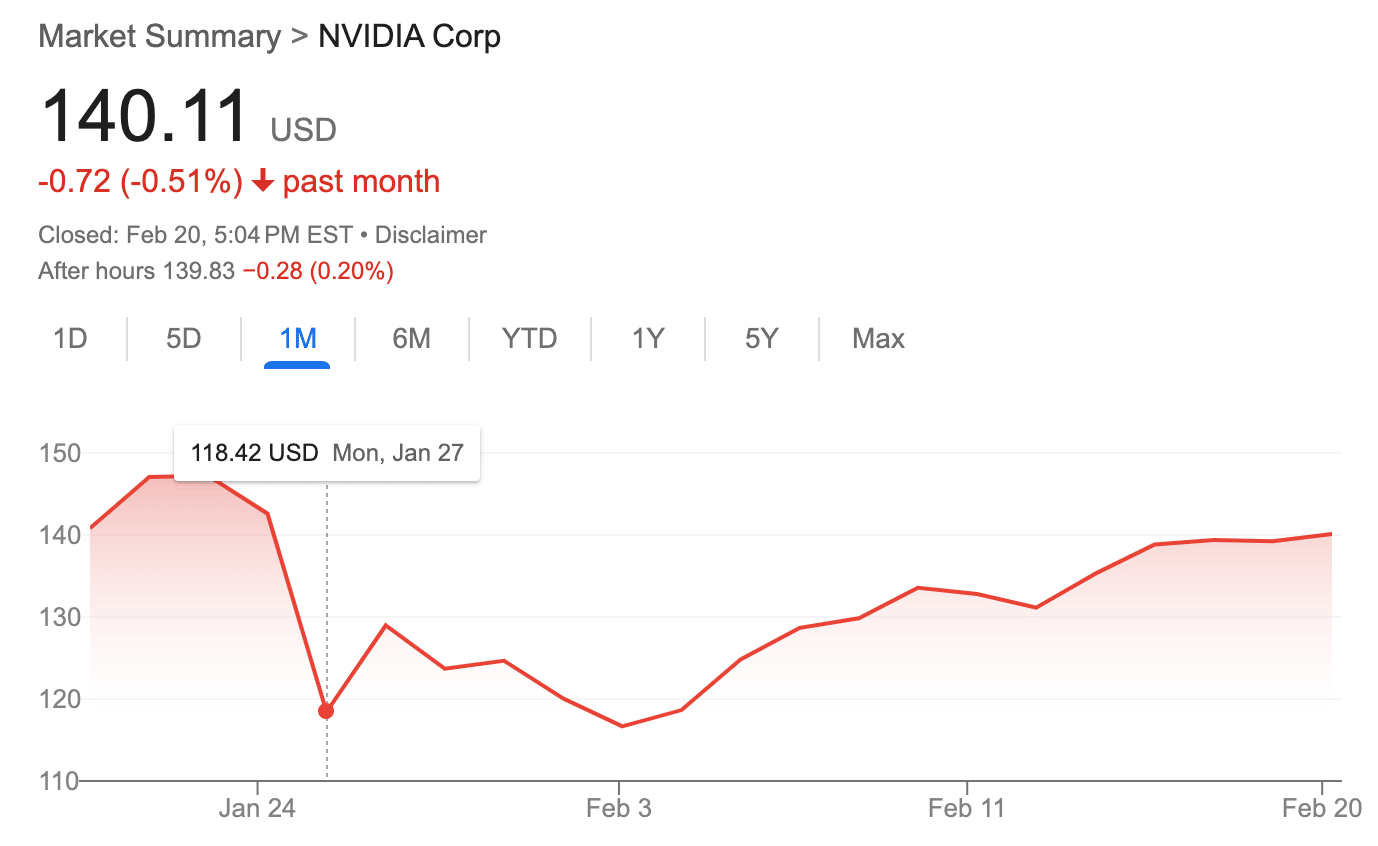
The stock is exactly where it was a month ago, before the DeepSeek “crisis.”
And if you look at the one-year chart, the DeepSeek drop is barely visible as a blip on Nvidia’s path to doubling its value in the past 365 days.
DeepSeek is a great accomplishment from a technical standpoint, but it was WAAAAY overblown by finance and tech commentators.
It was an epic narrative – a tiny Chinese upstart dethroning the biggest tech companies, and maybe reducing demand for Nvidia’s most advanced chips as a result.
With a month’s hindsight it just seems silly.
Today I’ll dissect what was (and is) cool about DeepSeek, and why those cool things haven’t changed the market.
Being China-based makes it very hard for DeepSeek to compete
There are many bad things about being born in one of the least-free countries in the world. The fact that no one trusts your large language model is not at the top of that list, but it is the factor that ensured DeepSeek’s technical success wouldn’t lead to big changes in the AI market.
And while the TikTok ban showed us that some American social-media users don’t mind having their biometrics stored in Chinese datacenters, the #1 rule of cybersecurity is to keep your sensitive data in democracies where lawyers and judges prevent misuse (and punish bad actors).
This is such a big deal that Zoom stopped routing meetings through Chinese datacenters at the behest of corporations that were forced into remote work during the pandemic. The moment someone who valued their data became a serious Zoom customer, China had to be removed from the equation.
DeepSeek R1 is one of the best models ever created. It is fast, cheap and open-source (more on that in a moment). If it had been released by a company in a trustworthy location, I suspect it would have been a much bigger deal in the long-term.
(I am imagining a New Zealand-based hedge fund doing the same thing, and I think in that scenario I’d be playing with NZ-DeepSeek every single day.)
Instead, it’s basically impossible to use DeepSeek directly if you have even an iota of concern about the security of your data, which I know nearly all Innovating with AI readers do. And that’s before you consider the fact the cheapness of the model’s training might have been overstated, and because the company is located in a low-trust/low-freedom country, nobody really has any way of verifying the numbers.
The bottom line – DeepSeek had a ton of business potential that was destroyed by the behavior of the government of the country in which its founders were born.
Open-source is not a major selling point (yet)
You can’t use a computer without benefiting from open-source software. In fact, just by reading this essay, you’ve probably interacted with dozens or hundreds of servers running Linux, Apache, MySQL and countless other open-source projects.
Open-source software is (to slightly oversimplify) in the public domain, which means anyone can use it for pretty much any reason without paying the creators.
In the pre-AI world, the business incentives for releasing open-source software were clear. The creators of the software could sell ancillary and enterprise-grade services and make tons of money, even if the base software was free. Here’s the CEO of MySQL explaining this strategy a couple years before he sold his open-source-software company for $1 billion.
The business model for open-source in AI is much less clear. (Importantly, OpenAI, despite its name, does not produce open-source anything.)
Because there is so much upside to creating the best model, and because training models is so expensive, most companies are incentivized to keep the inner workings of their models secret. The main exception is Meta, which has created the open-source Llama series of models. Still, Meta strategically hides certain things about Llama to make it harder for others to replicate its work, and the licensing agreement has some limitations at enterprise scale. Mistral is a small-but-mighty open-source competitor, founded by former Google and Meta employees.
The other big open-source model? DeepSeek.
In fact, by one common measurement, DeepSeek’s R1 model is by far the best open-source model that exists today.
Which leads to a fascinating question – why didn’t Meta’s stock tank when DeepSeek went public?
The answer, of course, is that open-source AI isn’t really a thing yet. In practice, you would need to spend tens of thousands of dollars to run a secure server to house your private DeepSeek or Llama AI model. Very large companies are doing this (and it solves the cybersecurity issues with DeepSeek), but it is completely unfeasible for most companies and individuals.
So, for now, open-source doesn’t really matter.
But give it a few years, and you will likely be able to run open-source models that are better than today’s DeepSeek R1 locally on your phone or laptop.
That’s where the open-source stuff changes the game, because it allows for nearly infinite replication of open-source AI, since the expensive-hardware barrier will have been eliminated.
Side note: DeepSeek openly displays its “chain of thought,” which is really cool to watch and is already pressuring private model creators like OpenAI to do the same. This was a valuable innovation and created meaningful competitive pressure.
In a way, DeepSeek and Llama and Mistral are ahead of their time, and will probably experience a renaissance when hardware costs catch up.
But for right now, the incredible generosity required to make DeepSeek open-source isn’t really adding to its commercial value.

Datacenter growth is a big deal, but it’s still a slow-moving ship
One of the big reasons that Nvidia is the second most valuable company in the world is the expectation that companies building gigantic AI datacenters will buy huge quantities of its most advanced chips.
This was supposedly the rationale for the DeepSeek-inspired sell-off of Nvidia stock: if DeepSeek can build an excellent model cheaply, not as many Nvidia chips might be necessary in the future, and the company’s sales might not be as great as expected.
(In retrospect, the sell-off was probably not rational, so take that “rationale” with a grain of salt.)
Someday Nvidia sales might slow down and the company might lose its luster, but for right now, they are benefitting from:
(A) being the market leader, and
(B) operating in an environment with extremely high capital expenditures, which requires decision-makers to act like a “slow-moving ship”
Take, for example, Meta’s plan to build a gigantic $65 billion AI datacenter in Louisiana. This facility will use 1.3 million Nvidia chips and its footprint is equivalent to that of a large part of Manhattan.
Projects like this don’t turn on a dime every time a new AI model comes out. They are long-term, hugely expensive, hugely intricate builds, and the people funding them are unlikely to suddenly shift gears and stop buying Nvidia’s state-of-the-art chips.
(To put it another way, this datacenter is not concerned about the rapid-fire news cycle ?)
So, as long a Nvidia produces the world’s best GPU chips, I think it’s going to be hard for them to produce anywhere near enough chips to satisfy demand – which means prices will stay high and Nvidia will remain incredibly valuable, regardless of how cheaply DeepSeek can operate.
Preparing for the uncertain tech future
One of the frameworks we teach students in The AI Consultancy Project is that a good consultant expects the unexpected. To succeed, you eventually need to accept that nobody knows what crazy AI news will be announced tomorrow.
There could be 10 more “DeepSeek moments” this year, or zero.
Thriving in the current highly volatile tech ecosystem means accepting that you cannot predict everything, no matter how smart or plugged-in you are. Instead of trying to express certainty (to yourself or to others), they key is to decide upon a clear plan for handling an uncertain future.
It’s sort of the difference between being a tour guide walking along a well-trodden path and being the first person to scale a remote mountain. The two treks require different approaches and different expectations. Right now, people who are willing to embrace uncertainty are going to have a huge head start as AI takes over more of society’s productive computer-based work.
